

TL;DR
- When a user says "show me a bag," guessing returns incoherent results; asking too many questions kills conversion
- Three iterations: static confidence weights (our guesses) → entropy-driven catalog stats (the catalog's signal) → knowledge graph + single LLM call (the right abstraction)
- The entropy approach broke on boolean dimensions, premature silhouette narrowing, and bad tag data — three independent failure modes
- A knowledge graph separate from the catalog solved the data quality problem that math alone couldn't fix
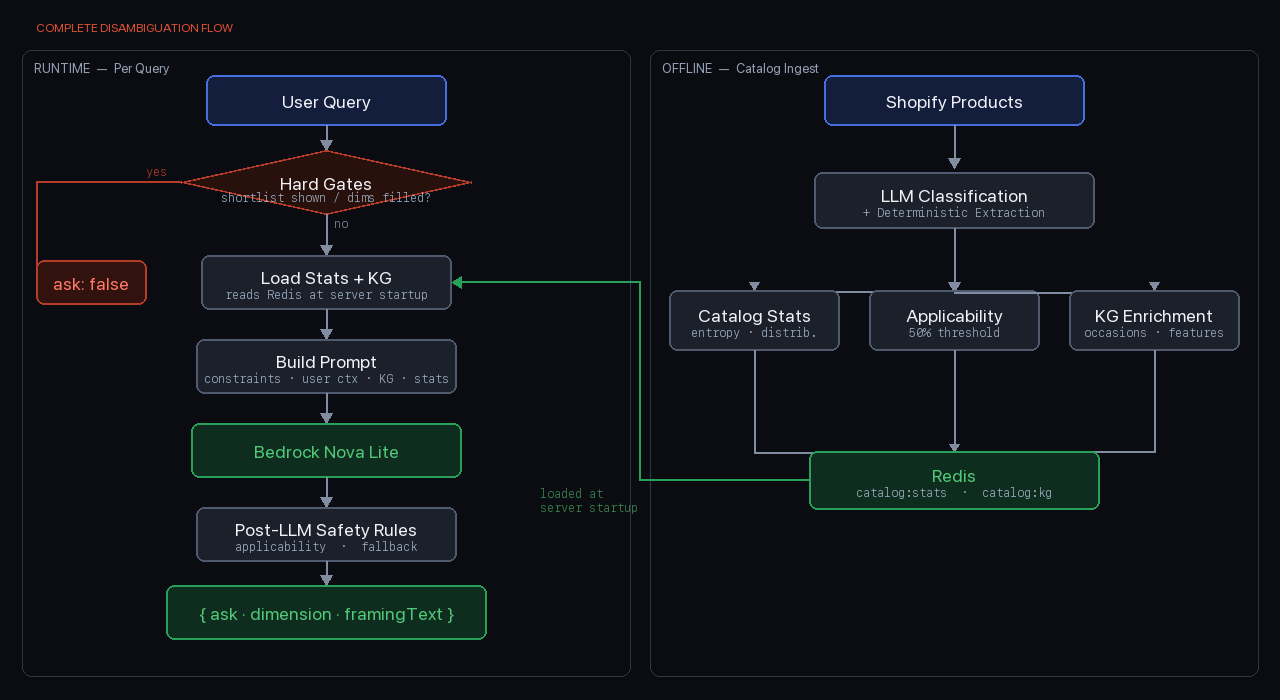
- The final engine makes one LLM call with four context blocks and two post-LLM safety rules; all expensive computation happens offline at ingest time
- Post-recommendation follow-ups are a completely separate problem — we solved them with LLM-emitted markers parsed from the streaming token output
The Problem No One Talks About
The hard part of building an AI shopping assistant isn't the recommendation engine. It's what happens before the recommendation engine even runs.
A user types: "Show me something for a trip."
Is that a cabin-size carry-on? A large check-in bag? A backpack? A travel accessory? A tote they can throw documents into? The query is perfectly valid English. It has clear intent. It is completely ambiguous from a search perspective.
Run this query straight into a vector search and you get a soup of results — bags from four different silhouettes, priced anywhere from ₹1,500 to ₹35,000, in every color and material. You return 5 cards, the user looks at them, finds nothing coherent, and drops off. The chatbot failed not because the search was bad, but because it ran a search it should have held.
The system needed to know when to search and when to ask. That deceptively simple requirement took us three iterations and one research rabbit hole to get right.
Iteration 1: Weights and Thresholds
Our first instinct was to treat disambiguation as a scoring problem.
We assigned confidence weights to every dimension based on how much it narrowed the search space. occasion was worth 30%. colour was worth 25%. silhouette contributed 20%. We set a threshold: if the total confidence score of the constraints extracted from a user query crossed 60%, we had enough to search. If it didn't, we looked at which high-priority dimension was still missing and asked for it — with 3-4 options as chips.
For a narrow query like "I need a red backpack for college", this worked well. Silhouette (backpack) was filled. Colour (red) was filled. Occasion (college) mapped to a known value. Score: 75%. Search immediately.
For a vague query like "something for a trip", only occasion was partially filled. Score: 30%. System flags missing silhouette as the highest-priority gap. Bot asks: "What kind of bag are you looking for?"
The logic was clean. It was also completely static.
The weights were our guesses. We sat in a room and decided that occasion was more important than colour. There was no data behind that. A user shopping for a cabin bag during a sale might care far more about price band than occasion. A user who already knows they want a backpack doesn't need to be asked about silhouette — they've already narrowed 80% of the search space. But the weight system didn't know any of that, because it never looked at the catalog.
Worse, the threshold itself was arbitrary. 60% meant nothing. We tuned it by feel, not by measuring what happened to the recommendations on either side of it.
It worked in demos. It broke in production.
Iteration 2: Entropy — Let the Catalog Decide
We stepped back and asked a different question: instead of us deciding which dimensions matter, what if the catalog told us?
The insight came from information theory. Entropy measures how spread out a distribution is. If 95% of products in the catalog share the same occasion value, asking about occasion tells you almost nothing. But if occasions are distributed evenly across five values, asking "what's the occasion?" immediately cuts the catalog into five meaningful slices. High entropy means high information gain. The bot should ask about the most entropic dimension first.
We built a catalog stats computation pass into the ingest pipeline. For every dimension — colour, silhouette, occasion, material, capacity — we measured the frequency distribution across the entire product catalog. The top values by frequency, the spread, the count of distinct values. This ran every time the catalog was refreshed and the results were stored in Redis.
The Applicability Matrix
Not every dimension is meaningful for every product type. Asking about luggage_size is relevant if you're looking at suitcases. It's irrelevant if you're looking at travel accessories. We built what we internally called the "multiplication table" — a matrix of dimensions vs. silhouettes computed during ingest. The rule: if at least 50% of products in a silhouette carry a value for a given dimension, that dimension is considered applicable to that silhouette. If not, it's masked out.
| Dimension | Luggage | Backpack | Tote | Duffle |
|---|---|---|---|---|
| luggage_size | yes | no | no | no |
| backpack_capacity | no | yes | no | no |
| occasion | yes | yes | yes | yes |
| water_resistant | yes | yes | no | yes |
This prevented the bot from asking a user who wanted a travel wallet about their preferred luggage size. The math said the dimension existed. The applicability matrix said it didn't apply here.
This was meaningfully better. But we hit three specific walls that stopped us from shipping it.
Three Problems That Broke the Entropy Approach
Why Boolean Dimensions Reported Entropy = 0
Entropy calculations rely on having a distribution to measure. Categorical dimensions — colour, occasion, silhouette — had clean arrays of distinct values with frequency counts. The math worked perfectly.
Boolean dimensions — water_resistant, laptop_compatible, on_sale — broke it.
By default, our stats pipeline wasn't populating topValues for boolean fields. It saw a true/false column and didn't know what to do with it. The result: the downstream entropy ranking treated all boolean dimensions as having a topValues array of length zero. Shannon entropy of an empty distribution is, mathematically, zero. So every boolean dimension looked completely useless for disambiguation — it would never be selected as a question to ask, even when it was genuinely differentiating.
The fix was simple once diagnosed: we explicitly injected both true and false with their respective counts into topValues for every boolean field during the ingest stats pass. After that, a dimension like laptop_compatible — where roughly 40% of backpacks had it and 60% didn't — correctly reported near-maximum entropy and got ranked as a useful clarifying question when the user was browsing backpacks.
The lesson: when you build a generalized system, edge cases in data representation can silently corrupt your math.
Premature Silhouette Narrowing
Consider a user who types: "show me bags."
At this point, they could mean anything. Luggage, backpacks, totes, duffles. The entropy-ranked dimension list would correctly identify silhouette as the first question to ask. But the second-highest entropy dimension in our catalog was luggage_size. And luggage_size only applies to the Luggage silhouette.
If the system selected luggage_size as its clarifying question before the user had specified their silhouette, it would force the user into the Luggage category before they had consciously made that decision. Asking "Are you looking for cabin size or check-in?" to someone who just said "show me bags" is jarring and presumptuous.
The applicability matrix was supposed to prevent this, but it could only prevent dimension questions for specific silhouettes the user had already declared. With no silhouette constraint, all dimensions appeared applicable by default — including silhouette-specific ones.
We added a guard: if the user has no silhouette constraint and the highest-entropy dimension is silhouette-specific, fall back to asking about silhouette first. Adding special-case guards to a system built on general principles is a warning sign.
Zero-Entropy from Bad Tags
Entropy calculations only work if the catalog data is good. Ours, for occasion, was not.
The occasion dimension was extracted from Shopify product tags. Brands rarely tag occasions precisely. Most products ended up defaulting to ["everyday"]. When 95% of a catalog has the same value for a dimension, the entropy of that dimension approaches zero — asking about it gives you almost no information.
The occasion dimension, which should have been one of the most useful clarifying signals, was mathematically useless. The bot had stopped asking about it almost entirely, because the data told it there was nothing to ask.
This was the hardest problem to fix purely mathematically. You cannot compute entropy from data that isn't there.
The Rufus Moment
We were stuck. The entropy system was clever but brittle. It broke on data quality problems. It required special-casing for edge cases that kept multiplying.
That's when we looked at how Amazon approaches the same problem with Rufus, their conversational shopping assistant.
Rufus doesn't rely purely on what's in the product catalog. It maintains a knowledge graph of product types — a semantic layer where nodes represent product categories and edges encode relationships like "cabin bags are used for short-haul travel" or "backpacks carry laptops" or "totes are appropriate for work occasions." This graph is built from curated knowledge, not extracted blindly from product tags.
The insight was clear: you need a layer of understood product knowledge that's separate from what your SKUs happen to say about themselves. Catalog data tells you what you have. A knowledge graph tells you what your products mean.
We built our own lightweight version: a KG enrichment layer computed at catalog ingest time. For each product type (silhouette), we extracted and curated the top 5 occasions, key features, use cases, and audience segments. Where tag extraction was unreliable, we seeded the graph with curated values. This knowledge graph lived in Redis alongside the catalog stats, ready to be loaded into the disambiguation engine at server startup.
The KG solved the zero-entropy occasion problem immediately. We weren't asking the catalog what occasions exist — we were asking the knowledge graph. The knowledge graph knew that a travel backpack is associated with adventure, weekend trips, and daily commutes regardless of how the brand tagged its SKUs.
How the KGDisambiguationEngine Works
With the knowledge graph in place, we made the final design shift: replace the rule-based entropy ranker with a single LLM call.
The entropy math, the applicability matrix, the dimension weights — all of it was our attempt to encode a decision that a language model is actually good at making, given the right context. We stopped trying to hand-code the intelligence and started giving the intelligence what it needed to decide.
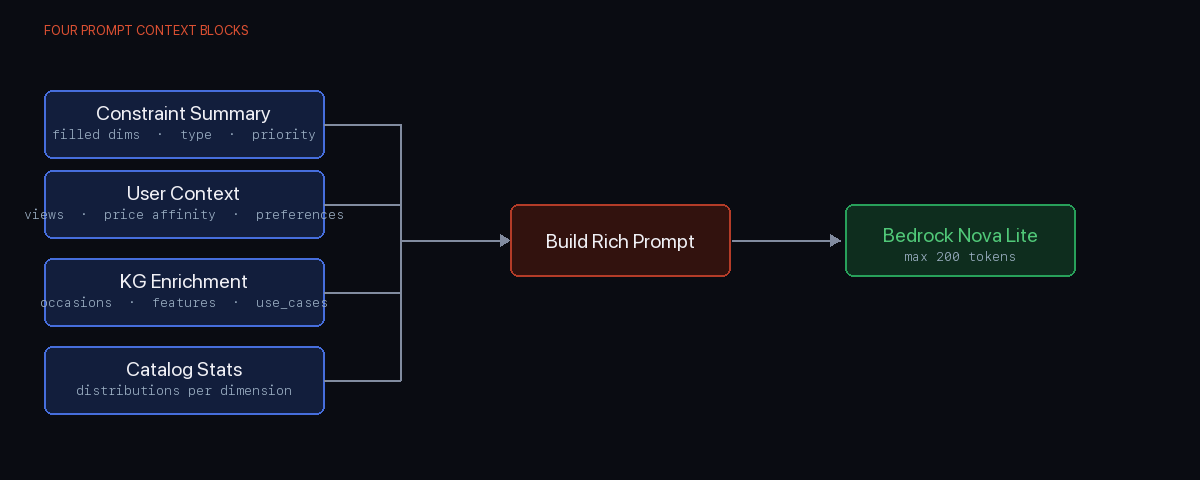
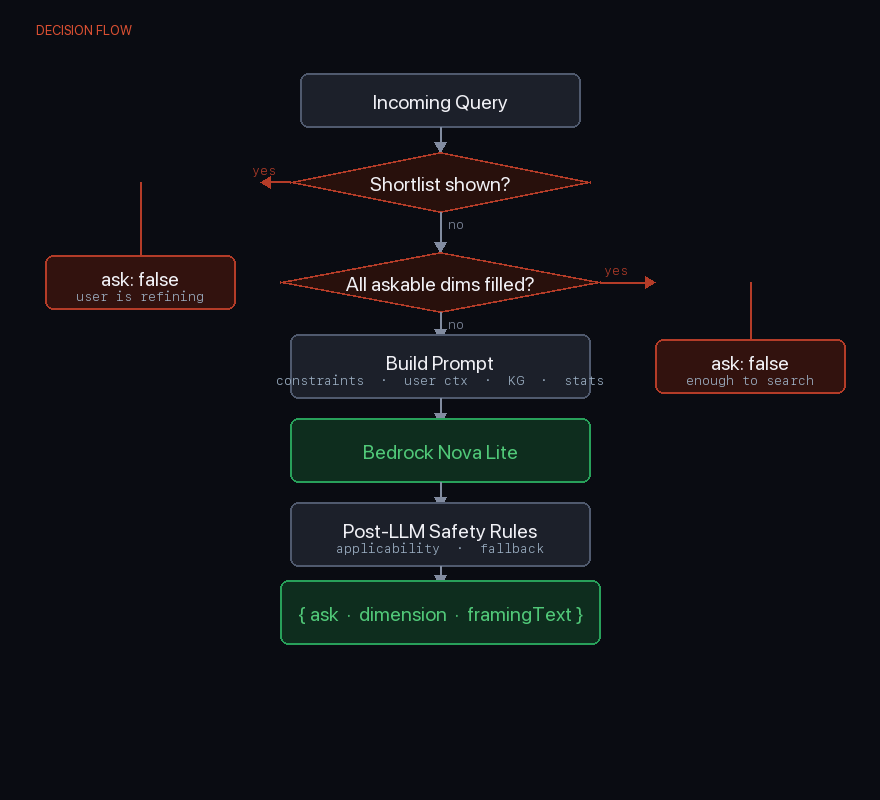
After two hard gates — if a shortlist has already been shown, or if all askable dimensions are already filled, the engine returns ask: false immediately without calling the LLM — the engine builds a rich prompt and fires a Bedrock Nova Lite call.
The prompt contains four context blocks:
- Constraint summary — what the user has already told us, with priority and type for each filled dimension
- User context — cross-session preferences: what product types they've viewed, their price affinity, any explicitly stated preferences
- KG enrichment block — for each product type detected in the query, the knowledge graph's list of occasions, features, and use cases
- Catalog stats block — the actual distribution of values for each unfilled dimension, so the LLM can judge whether asking a dimension is genuinely discriminating
The LLM returns a structured JSON:
{
"ask": true,
"dimension": "silhouette",
"framingText": "What kind of bag are you thinking about?"
}
The framingText is its own suggested phrasing for the question, which we use to make the question feel contextual rather than mechanical.
After the LLM responds, two post-LLM safety rules run before we act on its answer:
- Applicability override: if the chosen dimension doesn't apply to the user's current silhouette context, we suppress it
- Fallback selection: if the chosen dimension only applies to a subset of silhouettes but the user hasn't narrowed to one, we find a dimension that applies universally
How We Handle the Pre-Search vs. Post-Recommendation Split
Once we shipped the disambiguation engine, a second related question surfaced: what happens after the recommendation?
After the bot shows a user five carry-on recommendations, what should it offer next? This is a fundamentally different problem from pre-search disambiguation. Before the search, we're narrowing a 2,000-SKU catalog. After the search, we're guiding a user through five specific products they're already looking at.
The information the system needs is completely different: the descriptions of the specific products just shown, and the conversation history of this session. Pre-search, catalog stats matter. Post-recommendation, they're mostly irrelevant.
We solved this with LLM-emitted follow-up markers.
The product service's streaming prompt instructs the model to append a structured line at the end of every recommendation response:
FOLLOWUP: Any colour preference? | Need matching accessories? | Compare these two?
The streaming service watches the live token stream in real time, detects the FOLLOWUP: line, parses it into three chip objects, and publishes them as a bot_quick_replies event to the frontend. The frontend renders them as tappable chips before the user has even finished reading the response.
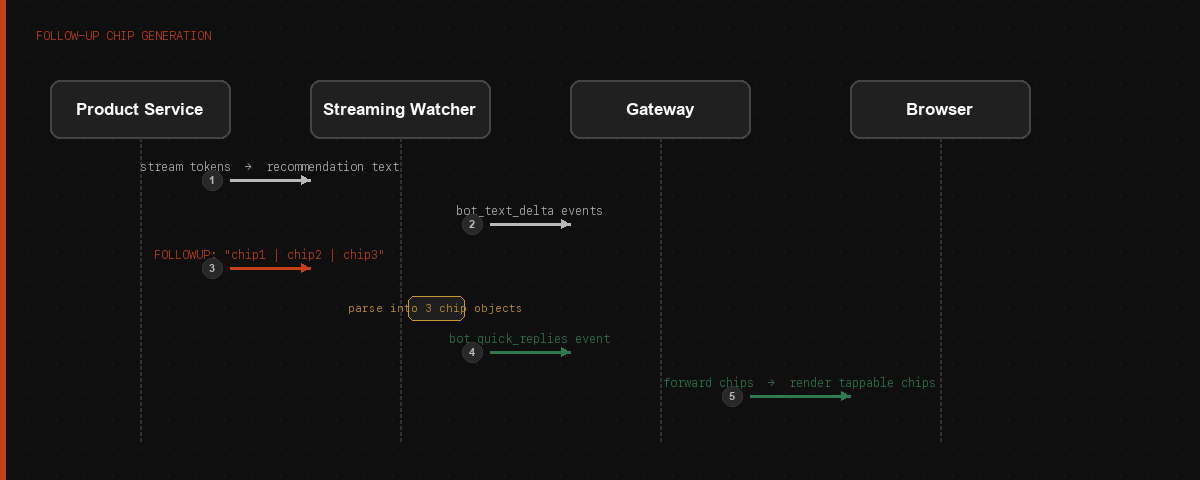
The chips are contextual to the current recommendation — the LLM knows what products it just showed and what the conversation history looks like, so it generates questions that are actually relevant to those products. "Any colour preference?" after showing five black bags. "Need matching accessories?" after showing carry-ons.
When a user clicks a follow-up chip, the pipeline detects the fu_* ID pattern and handles it differently from a fresh query: it routes to GO_DETAIL or GO_COMPARE rather than triggering a fresh disambiguation cycle.
The Ingest Pipeline: Where the Intelligence Lives at Rest
The disambiguation engine is fast at runtime because the ingest pipeline does heavy lifting at catalog-load time. Every time the product catalog is refreshed, the pipeline runs five stages:
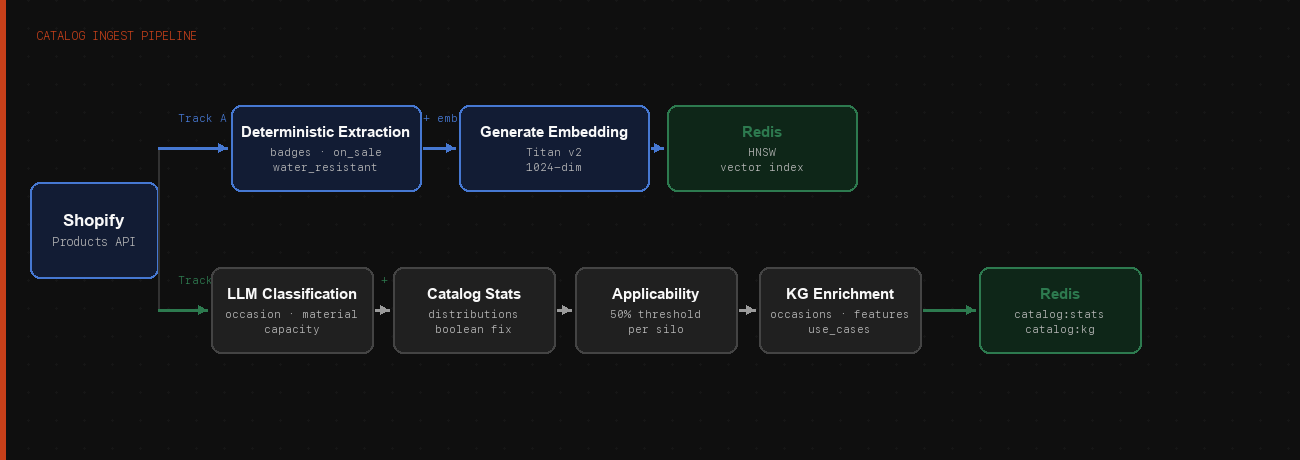
- Fetch and enrich — pull products from Shopify, run LLM classification for dimensions like occasion and material that can't be derived from structured fields
- Deterministic signal extraction — badges, on-sale flags, physical properties (
water_resistant,laptop_compatible) from tags and description regex - Compute catalog stats — frequency distributions per dimension, boolean
topValuesinjection, price percentiles - Compute dimension applicability — the 50% threshold matrix
- Compute KG enrichment — per-silhouette occasions, features, use cases, and audience segments
The result is two Redis keys — catalog:stats and catalog:kg — that the disambiguation engine loads at server startup. All the expensive computation happens offline. The runtime call is: one prompt construction, one LLM call, two rule checks, one response.
What Changed
The shift from the rule-based approach to the final engine was significant in practice, though we don't have formal A/B metrics to cite here. What we observed qualitatively:
Better question selection. The LLM, given catalog stats and KG context, consistently picked questions that reflected what the catalog could actually differentiate on — not what we guessed was important.
No more premature silhouette forcing. Because the LLM understands context, it doesn't ask a user who said "show me bags" about luggage_size. It asks about what kind of trip, or what silhouette they had in mind, in natural language.
Occasion questions that make sense. With the KG enrichment providing curated occasion vocabulary per silhouette, questions about occasion were finally useful. The bot stopped defaulting every product to "everyday."
Follow-ups that felt native. The LLM-emitted follow-up chips felt like natural conversation continuations rather than canned suggestions.
What We Got Wrong
Don't weight what you don't understand. Our first system assigned numerical confidence scores to dimensions we didn't have data for. The numbers felt precise. They were fabricated. Data-driven systems should be driven by data, not by the team's intuitions dressed up in percentages.
Entropy solves the right problem and ignores the right problems too. Information-theoretic framing was the right move — it made question selection principled rather than arbitrary. But entropy is only as good as the data underneath it. Garbage tag data produces zero-entropy dimensions that are actually highly differentiating. You need a knowledge layer that isn't purely derived from the catalog.
Edge cases in data representation can corrupt math silently. The boolean entropy bug didn't throw an error. It just made the system subtly wrong in a way that took us a while to diagnose. Treat data representation mismatches as bugs, not gaps.
LLMs are good at judgment calls. The decision of which question to ask depends on context, catalog shape, user history, and conversational moment. We tried to encode this judgment as math. The math kept breaking. Handing it to a language model with the right context worked better.
Separate the pre-search and post-recommendation problems. They share vocabulary but they're not the same problem. Pre-search disambiguation is about the catalog. Post-recommendation follow-up is about the products just shown. Mixing the two approaches made both worse.
We started with a spreadsheet full of made-up weights. We ended with a system where catalog data, a knowledge graph, and an LLM collaborate to make a decision that took us months to formalize in rules. The final code is simpler than any of the intermediate versions. That's usually how it goes.


