
TL;DR
- A McKinsey study found that employees burn nearly 1.8 hours per day just searching for information — that is roughly 25% of the workday gone before any real work starts.
- Enterprise data lives across spreadsheets, shared drives, local disks, email threads, and the heads of people who "just know things." None of these talk to each other.
- Pimcore is an open-source platform that combines Product Information Management (PIM), Master Data Management (MDM), Digital Asset Management (DAM), and a Content Management System (CMS) — all in one place.
- We walk through three integration architectures: Pimcore as the single master, Pimcore as a sync hub, and a hybrid model with domain ownership (our recommended approach).
- Pimcore's Data Hub, paired with AI, turns your structured data into something your team can actually query in natural language — no more hunting for the right person or the right folder.
- We are actively implementing this for enterprise clients across manufacturing, D2C, and B2B supply chains.
The Workday That Disappears Before It Starts
Picture a Monday morning at any mid-sized enterprise that runs manufacturing, manages a network of suppliers, operates warehouses, and sells through both D2C and B2B channels.
The operations lead opens three Google Sheets to cross-check SKU availability. A procurement manager digs through a SharePoint folder for the latest vendor contract — the one someone renamed last week. A warehouse supervisor sends a WhatsApp message asking if the updated packing spec was in "that Excel file or the other one." Meanwhile, the D2C team is working off a product catalogue that was last synced with the ERP... two months ago.
Nobody is being lazy here. They are all working hard. They are just spending a criminal amount of that effort finding things instead of doing things.
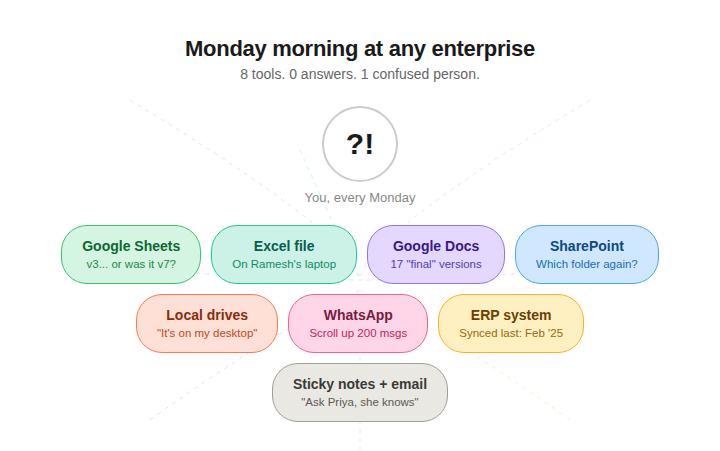
And the numbers back this up. A McKinsey report found that employees spend an average of 1.8 hours every single day searching for and gathering information. That translates to roughly 9.3 hours a week. A separate IDC study puts it even higher — about 2.5 hours per day, or 30% of the workday. An enterprise search survey from 2025 calculated that for a 50-person team, this adds up to over 8,300 hours lost per year. That is equivalent to four full-time employees doing absolutely nothing productive for twelve months straight.
The problem is not that people are bad at searching. The problem is that there is nothing unified to search.
The Tools That Were Never Meant to Be Your System of Record
Let us count what a typical enterprise with manufacturing, supplier, warehouse, D2C, and B2B operations actually uses to manage their data:
Google Sheets and Excel files — the de facto product catalogue for half the company. One version on someone's laptop. Another on Google Drive. A third attached to an email from February. All slightly different.
SharePoint and Google Drive — vendor contracts, product specs, compliance documents. Organized by whoever created the folder, which means not organized at all.
Local disks and desktops — the warehouse supervisor's laptop has "the real numbers." The designer's machine has the final product images. Nobody else can access either.
Notes and messaging apps — critical decisions made in Slack threads, WhatsApp groups, and sticky notes. Try finding a pricing decision from three weeks ago in a WhatsApp chat with 200 unread messages.
ERP, CRM, and eCommerce platforms — each with its own version of the truth about the same product, customer, or order.
Every one of these tools is fine at what it was built to do. The spreadsheet is a great spreadsheet. The shared drive is a decent file system. The ERP handles transactions well. But none of them were built to be the single source of truth for your entire business. And when you stitch them together with copy-paste, manual exports, and "ask Ramesh, he knows" — you get a system that technically works but practically fails every single day.
The real cost is not just wasted hours. It is wrong decisions made on stale data. It is the product that shipped with last quarter's pricing. It is the compliance document that was updated in one folder but not the other. It is the new hire who takes three months to become productive because half the knowledge lives in someone's head.
What a Single Source of Truth Actually Looks Like
The fix is not another spreadsheet. It is not a better folder structure. It is not a Notion workspace or a fancier shared drive.
What enterprises in this situation need is a platform that can:
- Store and structure all master data — products, digital assets, documents, customer records — in one governed place.
- Connect to existing systems (ERP, CRM, eCommerce) without forcing everyone to abandon their workflows overnight.
- Enforce data quality — validation rules, approval workflows, role-based access — so the data that goes in is actually trustworthy.
- Expose data through APIs — so any system, dashboard, or application that needs data can pull it from one canonical source.
- Be fully under your control — self-hosted, open-source, no vendor lock-in, no per-seat SaaS pricing that balloons as you scale.
This is where Pimcore comes in.
Pimcore: PIM + MDM + DAM + CMS in One Open-Source Platform
Pimcore is an open-source platform built on PHP and Symfony that brings together capabilities most enterprises buy from four or five separate vendors:
Product Information Management (PIM) — model, enrich, and manage product data with flexible data objects. Not rigid templates; you define the schema that fits your business.
Master Data Management (MDM) — govern all your core business entities (products, customers, suppliers, locations) with validation rules, workflows, and versioning.
Digital Asset Management (DAM) — store, organize, and distribute images, PDFs, videos, CAD files, and any other digital asset. Linked directly to the data objects they belong to.
Content Management System (CMS) — manage web content, landing pages, and portals. The content layer sits right next to the data layer, so your marketing team pulls from the same source as your warehouse.
Data Hub — a built-in data delivery and consumption layer with GraphQL APIs out of the box. This is how Pimcore talks to everything else — ERPs, storefronts, mobile apps, reporting dashboards, and (as we will get to shortly) AI systems.
All of this runs on your infrastructure. No per-seat licensing. No data leaving your servers unless you want it to. Full RBAC (role-based access control) to govern who sees what, who edits what, and who approves what.
Three Ways to Integrate Pimcore Into Your Enterprise
This is the architectural question every enterprise faces: we already have an ERP, a CRM, an eCommerce platform. Where does Pimcore fit, and how does data flow?
We have implemented three distinct patterns. Each fits a different stage of enterprise maturity.
Option 1: Pimcore as the Single Master
In this model, Pimcore is the only place where records are created. Every product, every asset, every piece of content is born in Pimcore. Downstream systems — ERP, CRM, eCommerce — are pure consumers. They receive data through webhooks or message queues, but they never originate it.
How it works: All creation, editing, enrichment, and approval happens inside Pimcore. When a product is published, Pimcore pushes an event to a message broker (Kafka, RabbitMQ, or Azure Service Bus). Each backend subscribes to the topics it cares about and consumes updates. Backends are read-only from a master data perspective.
This fits when: You are starting from scratch with no legacy systems, or you need the strictest possible data governance — every piece of data must pass validation and enrichment in Pimcore before any backend ever sees it.
The trade-off: Pimcore becomes critical infrastructure. If it goes down, no new records flow anywhere. Every team in the company must adopt Pimcore as their creation workflow, which is a significant change management effort.
Option 2: Pimcore as a Sync Hub
Here, records are born where they naturally belong. Products get created in the ERP. Customers get created in the CRM. Orders come from the eCommerce platform. Pimcore sits in the middle as an aggregation and enrichment layer — it pulls data from all backends, provides a unified view, enriches it with assets and translations, and optionally republishes to other channels.
How it works: Each backend retains full ownership of its records. Pimcore pulls data via scheduled API calls, or backends push updates via webhooks. Pimcore enriches the records (adding images, translations, marketing content) and can republish to portals or reporting dashboards.
This fits when: You have established legacy systems that teams rely on daily and cannot disrupt. Pimcore is introduced as a portal and enrichment layer without a big-bang migration.
The trade-off: Data in Pimcore may lag behind source systems (eventual consistency). Multiple systems can update the same record, so you need explicit conflict resolution rules. Data governance is fragmented.
Option 3: Hybrid with Domain Ownership (Our Recommendation)
This is the pattern we recommend for most enterprises with existing backend systems.
The principle is simple: each system owns what it does best. Pimcore owns product master data, digital assets, content, and translations. The ERP owns pricing, inventory, and finance. The CRM owns customer relationships and contracts. The eCommerce platform owns orders, carts, and checkout.
Nobody owns everything. Nobody fights over the same fields. Ownership is defined at the entity and field level.
How it works in practice — say you are launching a new product:
- A product manager creates the master record in Pimcore — name, category, descriptions, specs. Uploads images and documents through the DAM. Triggers a translation workflow.
- On approval, Pimcore emits a
product.createdevent to the message broker. The ERP picks it up and creates a SKU (adding its own pricing and stock data). The eCommerce platform creates a product listing using Pimcore's enriched content. The CRM gets a product reference for quoting. - Operational data flows back: the ERP sends pricing and stock updates to Pimcore for display. eCommerce sends order data back for reporting. But Pimcore never writes pricing — it only displays what the ERP provides.
The ownership rule is clean: if the data describes what something is — Pimcore owns it. If the data describes what happened with it — the operational backend owns it.
Why this works: No single point of failure. Backend teams keep their workflows. Data conflicts are eliminated because ownership is explicit per field. And it scales — adding a new channel or backend is just another subscriber on the message broker.
The trade-off: Higher upfront design effort. You need to define domain boundaries clearly, build a canonical data model, and enforce discipline across teams. But every enterprise we have worked with has found the initial investment pays for itself within the first quarter of operation.
The AI Layer: Ask Your Data, Do Not Hunt for It
Here is where things get genuinely exciting.
Pimcore's Data Hub exposes all your structured data — products, assets, documents, objects — through a GraphQL API. You configure what is exposed, to whom, and with what permissions. The built-in GraphiQL explorer lets you test queries right inside Pimcore.
Now combine that with an AI layer.
Instead of your procurement team messaging five people to find the latest vendor spec for a specific component, they open a query interface and ask: "Show me the approved packaging specification for SKU-4821, last updated version."
Instead of a new hire spending their first week figuring out which folder has the onboarding documents, they ask: "What is our standard QA checklist for incoming raw materials?"
Instead of the sales team digging through three systems to prep for a client call, they ask: "Give me the current catalogue, pricing, and last three orders for Mehta Industries."
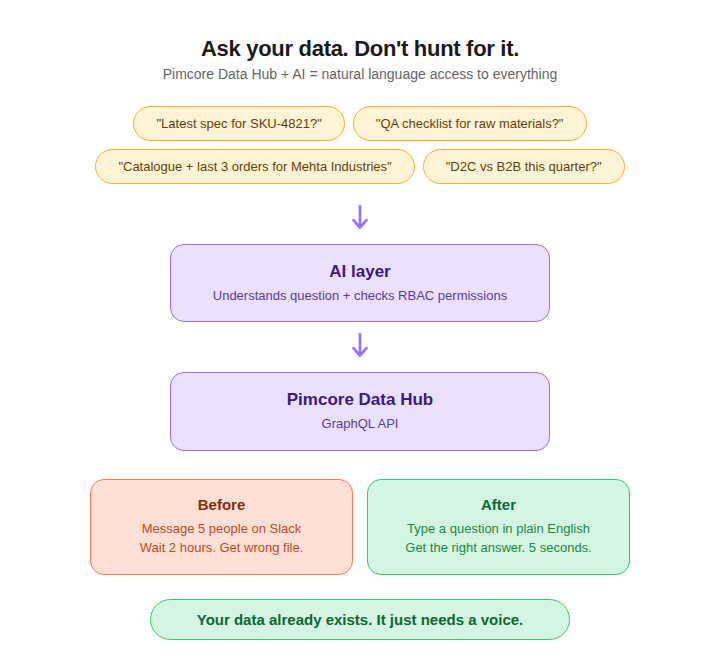
The AI layer sits on top of Pimcore's Data Hub. It consumes the same GraphQL endpoints, respects the same RBAC permissions (a warehouse manager cannot query financial data they do not have access to), and returns answers grounded in your actual, governed, structured data — not hallucinated guesses from the open internet.
This is not a futuristic concept. We are actively building this for clients right now. The combination of Pimcore's structured data backbone with AI-powered natural language querying eliminates the two biggest time sinks in enterprise operations: searching for the right information and searching for the right person who knows something.
Your data already exists. It just needs a home where both humans and AI can find it.
What We Are Building for Our Clients
We are implementing exactly this architecture — Pimcore as the data backbone with the hybrid domain ownership model — for enterprise clients across manufacturing, supply chain, D2C, and B2B verticals.
The pattern is consistent: scattered data across a dozen tools, operational teams burning hours on data reconciliation instead of actual operations, and no single place where anyone (human or machine) can go to get a trustworthy answer.
Pimcore gives them that place. The Data Hub with AI gives them the interface.


