
TL;DR
- Our content API fetched from Shopify and Strapi on every request, taking 300ms to 2 seconds per page load
- During sale-day traffic (2-3x normal), Strapi started failing under load and requests timed out
- We built a three-layer cache: entity cache, pre-assembled response cache, and an automatic dependency graph
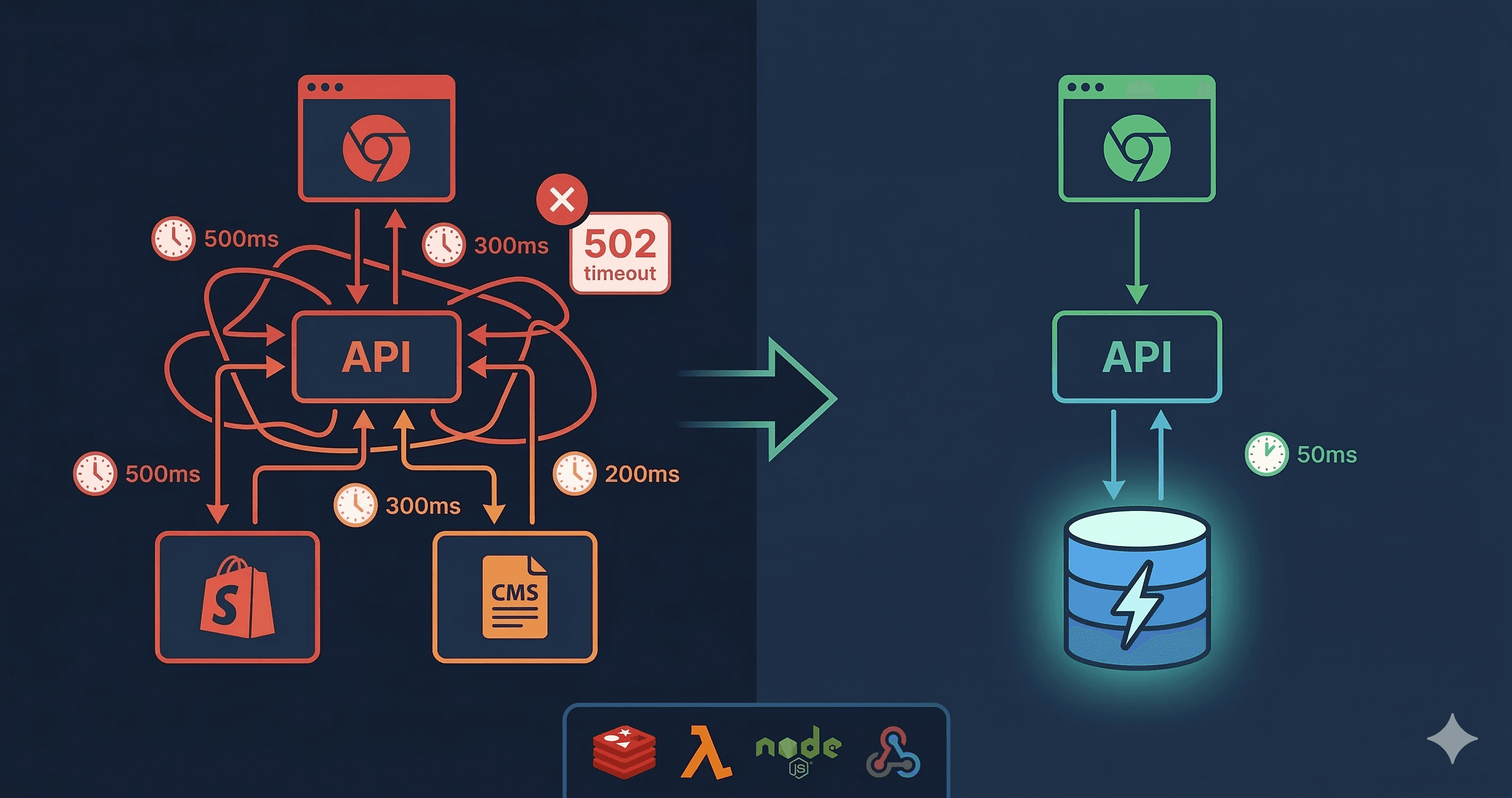
- API responses dropped from 500-800ms to 50-120ms (single Redis GET instead of 5-10 external API calls)
- The entire system fits in 4MB of Redis: 119 pre-assembled responses, 299 entity caches, 134 dependency graph entries
- Cache invalidation is fully automatic via webhooks. No TTLs, no polling, no manual config
We run an e-commerce platform on Shopify with a headless Next.js frontend. Product data lives in Shopify. Page layouts, blogs, ingredients, and all CMS content lives in Strapi. Every API response stitches data from both sources together.
For the first few months, this worked fine. Then we started adding more content. Rich product pages with linked ingredients and root causes. Blog posts referencing products. Collection pages pulling 30+ products each. The homepage alone needed data from 35 different entities.
That is when things started breaking.
How bad was it?
Every page load triggered 5-10 API calls to Shopify and Strapi. Each call took 200-400ms. A single homepage request took 500-800ms to assemble. Product pages sat around 300-500ms.
On a normal day with 100K user sessions, this was tolerable. Slow, but functional.
Then sale day hit. Traffic doubled, sometimes tripled. Strapi could not handle the concurrent load. Requests queued up, response times climbed past 2 seconds, and some requests just failed. The CMS that powered our entire content layer was the single point of failure, and it was failing at the exact moment we needed it most.
The numbers: roughly 30-50 lakh daily revenue, 2% conversion rate, 700 rupee average order value. Every second of degraded performance during a sale was real money walking out the door.
Why wasn't entity caching enough?
The obvious first move was caching individual entities in Redis. Fetch a product from Strapi once, cache it, skip the API call next time. We did this for every entity type.
It helped. Individual lookups dropped from 300ms to 5-10ms. But a single page is not one entity.
Our homepage pulls data from a template, which references products, which link to ingredients and root causes, which link back to other products. That is 35 Redis GETs, plus all the merge logic to stitch Shopify product data with Strapi content data, plus relation resolution to hydrate nested references. Response times improved to 100-200ms, but still not fast enough when multiplied by thousands of concurrent users during a sale.
And then there was the real problem: cache invalidation.
Someone updates a product in Strapi. Which cached pages need refreshing? The product page, obviously. But also the homepage, because it shows bestsellers. Three collection pages that include this product. Two blog posts that reference it. The search page. That is 8+ pages affected by a single product edit.
We looked at three options:
Short TTLs. Cache everything for 60 seconds, let it expire and rebuild. But during a sale, even 30 seconds of stale pricing is a problem. And when the TTL expires under high traffic, you get a thundering herd: hundreds of requests all trying to rebuild the same cache simultaneously, hammering Strapi again.
Manual dependency mapping. Maintain a config that says "product X appears on pages Y, Z." With 80+ products, 38 collections, and 15+ CMS pages, this was unmaintainable. Every time a content editor added a product to a collection, the dependency map would need updating.
Event-driven invalidation with automatic tracking. Let the system figure out dependencies on its own, and use webhooks to trigger invalidation in real-time. This is what we built.
How does the pre-assembled cache work?
We built three layers, each solving a different problem.
Layer 1: Entity Cache. Individual Strapi and Shopify entities stored in Redis. No TTL. Updated only when Strapi fires a webhook saying something changed. This is the raw material: 299 entries covering every product, collection, blog, template, ingredient, and more.
Layer 2: Assembled Cache. Pre-built, fully merged API responses. The homepage is not assembled on-the-fly from 35 entities anymore. Instead, the complete 86KB JSON response sits in Redis, ready to serve. One GET, one response, done. We have 119 of these covering every page, product, collection, blog, and singleton (header, footer, cart, search).
Layer 3: Dependency Graph. The brain of the system. It automatically tracks which entities each assembled response depends on, stored as two Redis indexes that tell us exactly what to invalidate when something changes.
The request flow is simple. A request comes in, middleware checks the assembled cache. Hit? Return the pre-built response. Miss? Fall through to the normal handler, which builds the response from entity caches, and the result gets stored as a new assembled entry.
How does the dependency graph track itself?
This is the part that made the whole system work.
When a page gets assembled for the first time, the system watches every entity it touches during the process. The homepage handler calls the page content service, which fetches a template, which references five products, which link to three ingredients and two root causes. Every entity fetched gets recorded.
By the end, we have a complete dependency list: "the homepage depends on these 35 entities."
This gets stored as two indexes in Redis:
Forward index answers: "What entities does this page need?"
page-deps:pages:index -> {products:amla-hair-oil, products:keshpallav, templates:women, ...}
Reverse index answers: "What pages use this entity?"
entity-tags:products:amla-hair-oil -> {pages:index, collections:bestseller, collections:hair-oil, ...}
That reverse index is everything. When someone edits the "Amla Hair Oil" product in Strapi, one SET lookup tells us: 18 assembled pages depend on this product. Invalidate all 18, rebuild them, and every user sees fresh data.
The tracking happens transparently using Node.js AsyncLocalStorage. Think of it as a request-scoped notepad that follows the code through async operations. Content services do not need annotations, decorators, or any awareness of tracking. They fetch data normally, and the system records what they touched.
// This is all it takes inside a content service
DependencyTracker.track(`products:${handle}`);
The dependency graph also cleans up after itself. If a page redesign drops a product reference, the next assembly captures the new dependency set and removes stale reverse entries. Zero maintenance.
How do changes propagate in real-time?
No TTLs. No polling. No cron jobs scanning for stale data.
When a content editor publishes a change in Strapi, it fires a webhook to our API. Here is what happens in the next few hundred milliseconds:
- Webhook handler receives the event with the entity's document ID
- Handler fetches the updated entity from Strapi and refreshes the entity cache in Redis
- System checks the reverse dependency index for that entity
- All affected assembled caches get deleted immediately
- System rebuilds them in the background with the fresh entity data
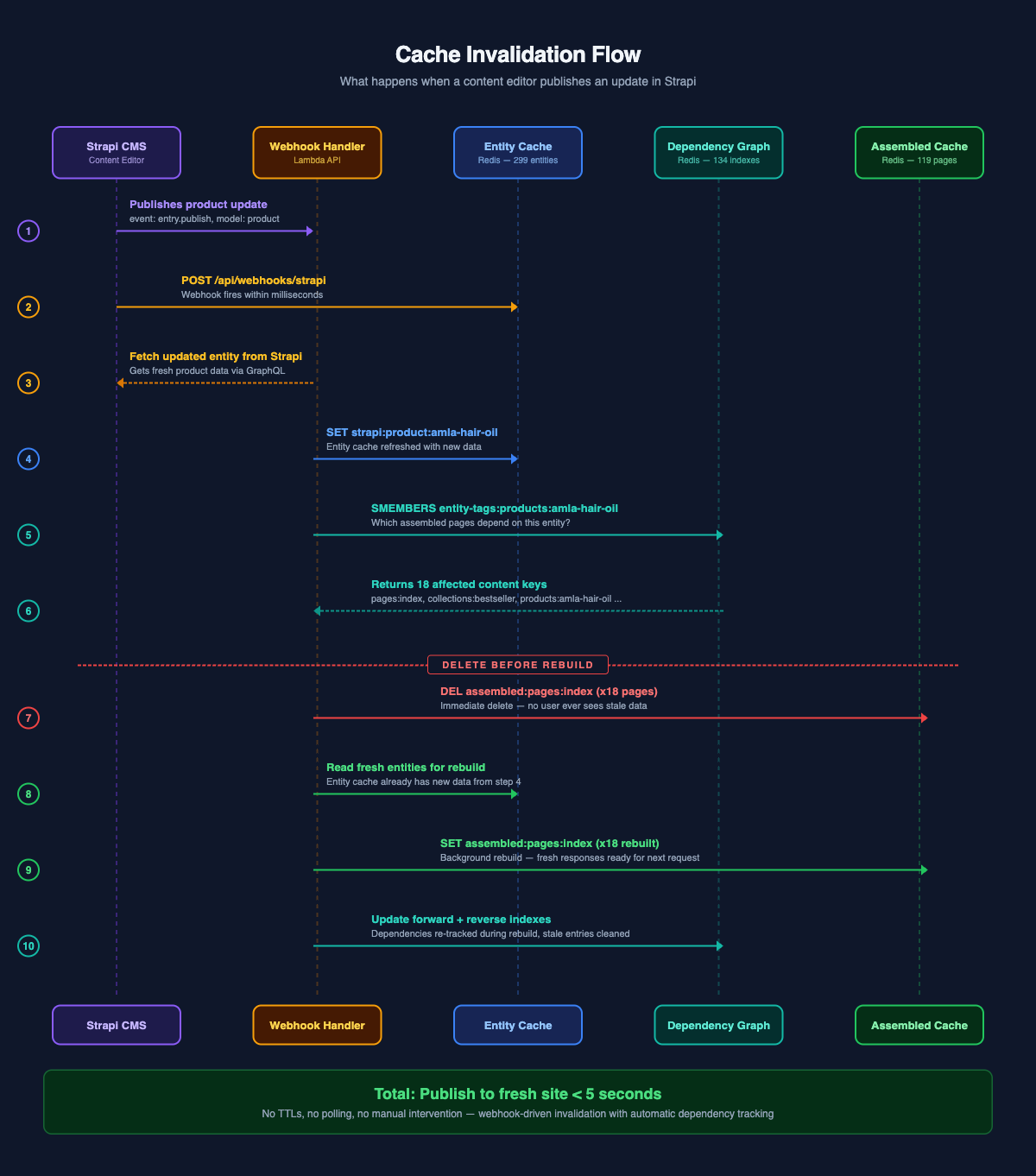
The critical design choice: delete before rebuild. During the brief rebuild window, any incoming request for that page gets a cache miss, falls through to on-demand assembly with the already-fresh entity cache, and serves correct data. No user ever sees a stale snapshot.
There is also cascade invalidation for bidirectional relationships. Products reference ingredients. Ingredients reference products. If we update a product and its linked ingredients change, the system detects the difference between old and new relations, refreshes the affected ingredient caches, and invalidates their dependent pages too. One edit can ripple through the graph, and the system handles it automatically by comparing the old cached version with the new one.
The result: a content editor hits "Publish" in Strapi, and the live site reflects the change within seconds. No deploy, no cache flush, no manual intervention.
What does the middleware look like?
The assembled cache is a middleware layer that wraps content handlers. It is the outermost layer in the chain, meaning it intercepts requests before any business logic runs.
export const handler = errorBoundary(
withAssembledCache(
withDependencyTracking(route)
)
);
withAssembledCache checks Redis for a pre-built response. On a hit, it returns immediately without invoking anything downstream. On a miss, it lets the request flow through, and after a successful response, it caches the result as a fire-and-forget operation. The response goes to the client first; the cache write happens asynchronously.
withDependencyTracking wraps the handler in an AsyncLocalStorage context. After the response is sent, it captures all tracked entities and writes the forward and reverse indexes to Redis. Again, fire-and-forget. Cache bookkeeping never delays the user's response.
Not every endpoint gets assembled. Paginated endpoints are skipped because each page/offset combination would need its own cache entry. Random selection endpoints are skipped because the result is different every time. Nested collection routes (like "products in this collection") are skipped for the same reason.
// Pagination params? Skip assembled cache.
if (queryParams.limit || queryParams.offset) {
return wrappedHandler(event);
}
What did the numbers look like after?
| Metric | Before | After |
|---|---|---|
| Homepage response | 500-800ms | 50-120ms |
| Product page response | 300-500ms | 50-100ms |
| API calls to Strapi per page load | 5-10 | 0 (cache hit) |
| Sale-day request failures | Timeouts, 502s | Zero |
| Time to reflect CMS changes | Unknown (TTL-based) | Under 5 seconds |
| Total Redis memory | N/A | 4MB |
The full system: 119 assembled responses, 299 entity caches, 54 forward dependency entries, 134 reverse dependency entries. The largest assembled response (homepage) is 86KB. The smallest (header) is 6KB.
One product can fan out to 18 dependent pages. One author affects 15 content keys. The dependency graph handles this automatically without any manual mapping.
During load testing with 3x normal traffic, the API served the same 50-120ms responses. Strapi saw zero load from user-facing requests because every response was already sitting in Redis.
What did we get wrong?
We built entity caching first and assembled caching second. In hindsight, we should have gone straight to pre-assembled responses. Entity caching was a stepping stone that taught us about the invalidation problem, but it added a layer of complexity we could have skipped.
The 50-120ms still includes overhead beyond our control. The Redis GET itself takes under 5ms within the VPC. The rest is Lambda warm-up, TLS handshake, and API Gateway routing. We initially thought we had "2ms responses" because that is what Redis reported. The real end-to-end number includes everything between the user and Redis. Still a 10x improvement, but it pays to be honest about where the time goes.
Bulk operations are not optimized yet. When a product sync updates 50 products at once, each one triggers its own cascade of invalidations and rebuilds. Some assembled pages get rebuilt multiple times in quick succession. Batching these invalidations into a queue with deduplication is next on the list.
No compression on large responses. The homepage is 86KB of JSON. With gzip, that would drop to roughly 15-20KB. We have not added response compression in the assembled cache layer yet.
What would we tell someone building this?
Start with the dependency graph. That was the hard part and the most valuable part. Getting the cache to work is straightforward. Knowing what to invalidate when something changes is where every caching system either succeeds or slowly rots into serving stale data.
Use webhooks, not TTLs. If your CMS supports webhooks on publish, you can eliminate time-based expiry entirely. Your cache is always either fresh or being rebuilt. There is no window of "probably fresh enough."
Pre-assemble at the response level, not the entity level. The difference between serving one cached response and making 35 cache lookups plus merge logic is the difference between your site staying up during a flash sale and your on-call getting paged.
Measure end-to-end, not just the cache layer. We thought we had 2ms responses. We actually had 50-120ms responses. Still a 10x win. But if we had built our capacity planning around that 2ms number, we would have been surprised the first time real traffic showed up.


