
TL;DR
- Semantic Kernel's AWS Bedrock connector crashes with
ValidationExceptionwhen the LLM makes multiple tool calls in a single response - Root cause: each tool result is sent as a separate
role=usermessage — Bedrock's Converse API requires all tool results from one assistant turn to be batched into a single message - The fix: patch the message assembly logic to collect all tool results and send them in one batched
role=usermessage - This bug only triggers when the LLM batches multiple tool calls — single tool calls work fine
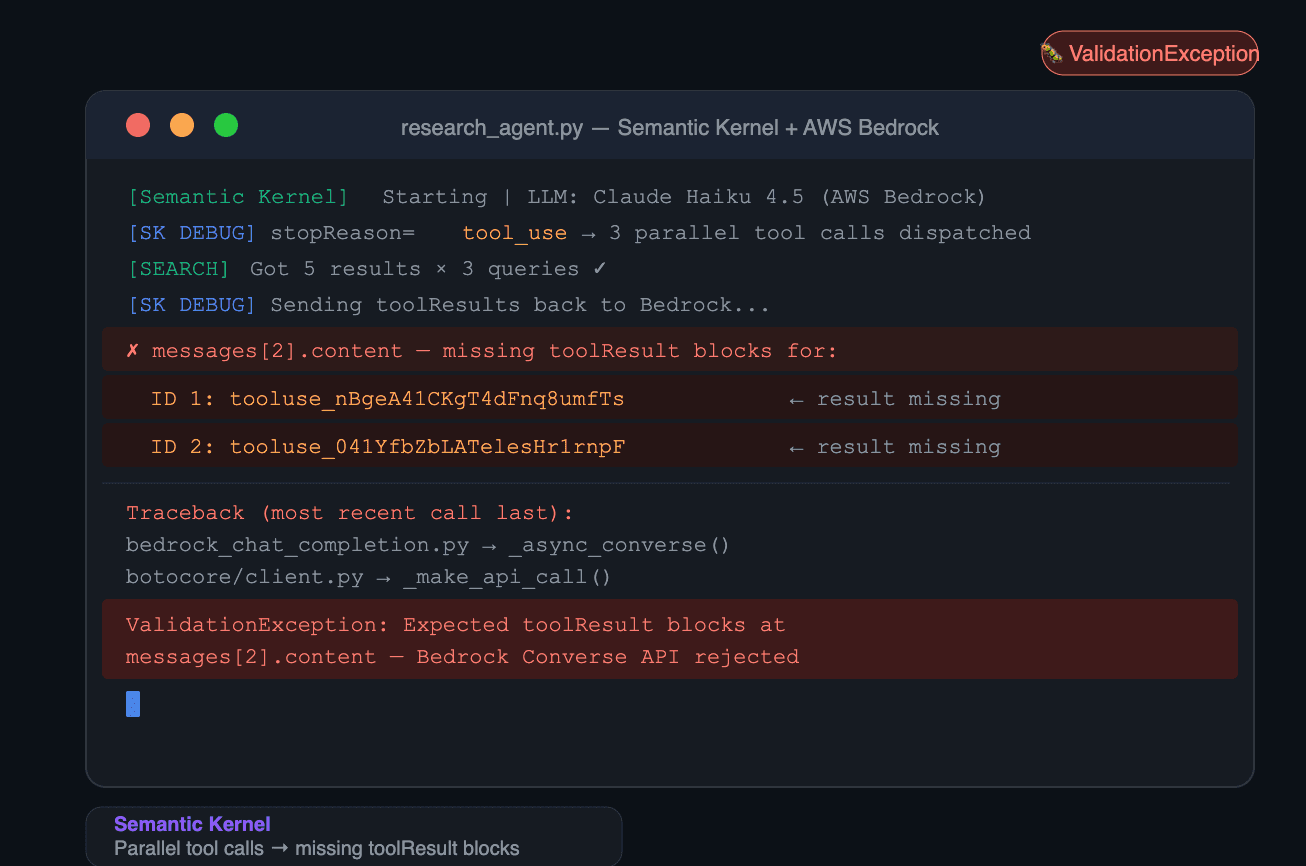
How We Found It
While benchmarking 6 agent frameworks on the same multi-agent research task — 3 parallel researchers, 1 analyst, all using Claude Haiku 4.5 via AWS Bedrock — Semantic Kernel was the only framework that crashed.
The task ran fine with single tool calls. The moment the LLM responded with multiple tool calls in one turn, the whole thing went down with a ValidationException.
Here's the exact error:
botocore.errorfactory.ValidationException: An error occurred (ValidationException)
when calling the Converse operation: Expected toolResult blocks at
messages.2.content for the following Ids:
tooluse_nBgeA41CKgT4dFnq8umfTs, tooluse_041YfbZbLATelesHr1rnpF
Bedrock expected both tool results to be in messages[2] as a single batched message. Instead, Semantic Kernel sent them as two separate role=user messages.
What AWS Bedrock Requires
AWS Bedrock's Converse API has a strict rule: all tool results from a single assistant response must be batched into one role=user message.
When the LLM responds with multiple tool calls in one turn:
assistant → [toolUse A, toolUse B, toolUse C]
Bedrock expects the next message to be:
user → [toolResult A, toolResult B, toolResult C] ← all in ONE message
Sending them separately causes an immediate ValidationException:
user → [toolResult A] ← message index 2
user → [toolResult B] ← message index 3 ← Bedrock rejects this
user → [toolResult C] ← message index 4 ← Bedrock rejects this
What Semantic Kernel Was Doing
The debug logs showed exactly what was happening before the fix. Each tool result was being sent as its own separate role=user message:
[SK DEBUG] SENDING TO BEDROCK — messages array:
[0] role=user | content=[{"text": "Research this topic: ..."}]
[1] role=asst | content=[{"toolUse": id=tooluse_nBgeA41C ...},
{"toolUse": id=tooluse_041YfbZb ...}]
[2] role=user | content=[{"toolResult": {"toolUseId": "tooluse_nBgeA41C" ...}}]
[3] role=user | content=[{"toolResult": {"toolUseId": "tooluse_041YfbZb" ...}}]
Message [2] contains the first tool result. Message [3] contains the second. Bedrock sees two consecutive role=user messages after an assistant turn with two tool calls — and throws:
Expected toolResult blocks at messages.2.content for the following Ids:
tooluse_nBgeA41CKgT4dFnq8umfTs, tooluse_041YfbZbLATelesHr1rnpF
It expected both IDs to be in messages[2]. The second one was in messages[3].
The Fix
The fix is to collect all tool results that belong to the same assistant turn and merge them into a single role=user message before sending to Bedrock.
Before (broken) — bedrock_chat_completion.py:
def _prepare_chat_history_for_request(self, chat_history, role_key="role", content_key="content"):
messages: list[dict[str, Any]] = []
for message in chat_history.messages:
if message.role == AuthorRole.SYSTEM:
continue
messages.append(MESSAGE_CONVERTERS[message.role](message)) # appends every message separately
return messages
Each tool result is converted and appended as its own role=user message. Two tool results = two consecutive user messages. Bedrock rejects this.
After (fixed):
def _prepare_chat_history_for_request(self, chat_history, role_key="role", content_key="content"):
messages: list[dict[str, Any]] = []
for message in chat_history.messages:
if message.role == AuthorRole.SYSTEM:
continue
formatted = MESSAGE_CONVERTERS[message.role](message)
# Batch consecutive tool results into a single user message (Bedrock requires this)
if (
formatted["role"] == "user"
and messages
and messages[-1]["role"] == "user"
and any("toolResult" in block for block in formatted["content"])
):
messages[-1]["content"].extend(formatted["content"]) # merge into previous user message
else:
messages.append(formatted)
return messages
Instead of appending every message unconditionally, the fix checks: if the new message is a role=user containing a toolResult, and the previous message is also role=user, merge the content blocks together. All tool results from one assistant turn end up in a single message.
After the fix, the debug logs confirmed the correct structure:
[SK DEBUG] SENDING TO BEDROCK — messages array:
[0] role=user | content=[{"text": "Research this topic: ..."}]
[1] role=asst | content=[{"toolUse": id=tooluse_M54itqkV ...},
{"toolUse": id=tooluse_j7wPdr1Y ...},
{"toolUse": id=tooluse_HhhVJnGD ...}]
[2] role=user | 3 toolResult(s) BATCHED in ONE message:
toolResult[0] id=tooluse_M54itqkVEwEVHAeVQoXPxW
toolResult[1] id=tooluse_j7wPdr1Y3em1lpZ3qhvLd4
toolResult[2] id=tooluse_HhhVJnGDq7yGSjPsfl7IKc
All three tool results in one message at index [2]. Bedrock accepted it. The agent ran to completion.
Before vs After — Full Log Comparison
Before fix — crashes at ValidationException
[SK DEBUG] SENDING TO BEDROCK — messages array:
[0] role=user | content=[{"text": "Research this topic: Key features..."}]
[1] role=asst | content=[{"toolUse": id=tooluse_kDfdAQQV ...},
{"toolUse": id=tooluse_nBgeA41C ...}]
[2] role=user | content=[{"toolResult": {"toolUseId": "tooluse_kDfdAQQV", ...}}]
[3] role=user | content=[{"toolResult": {"toolUseId": "tooluse_nBgeA41C", ...}}]
botocore.errorfactory.ValidationException: An error occurred (ValidationException)
when calling the Converse operation: Expected toolResult blocks at
messages.2.content for the following Ids:
tooluse_nBgeA41CKgT4dFnq8umfTs, tooluse_041YfbZbLATelesHr1rnpF
After fix — runs clean
[SK DEBUG] SENDING TO BEDROCK — messages array:
[0] role=user | content=[{"text": "Research this topic: Key features..."}]
[1] role=asst | content=[{"toolUse": id=tooluse_HPOgsibm ...},
{"toolUse": id=tooluse_4afqEPnG ...},
{"toolUse": id=tooluse_uhyVNmnW ...}]
[2] role=user | 3 toolResult(s) BATCHED in ONE message:
toolResult[0] id=tooluse_HPOgsibmFJyKtslirmfeVn
toolResult[1] id=tooluse_4afqEPnGGcEWHJMWqktY1V
toolResult[2] id=tooluse_uhyVNmnW4N2C9B8NJj4JDb
[SK DEBUG] LLM RESPONSE:
stopReason=end_turn
output={"message": {"role": "assistant", "content": [{"text": "## Comprehensive
Research Summary...
Why This Happens
This is a connector-level bug, not a Semantic Kernel core bug. The bedrock_chat_completion.py connector in Semantic Kernel was not handling the case where the LLM returns multiple tool calls in a single response — a pattern that is completely valid in the Claude API and common when the model decides to batch parallel searches.
The bug only surfaces when:
- You're using the AWS Bedrock connector (not the direct Anthropic API)
- The LLM makes more than one tool call in a single response turn
Single tool call per turn works fine. The moment the LLM decides to batch calls — which happens frequently in research-style tasks — the connector breaks.
How to Reproduce
import asyncio
from semantic_kernel.agents import ChatCompletionAgent
from semantic_kernel.connectors.ai.bedrock import BedrockChatCompletion
from semantic_kernel.kernel import Kernel
from semantic_kernel.functions import kernel_function
kernel = Kernel()
service = BedrockChatCompletion(model_id="anthropic.claude-haiku-4-5-20251001-v1:0")
kernel.add_service(service)
# Define two tools
@kernel_function(name="search_web")
def search_web(query: str) -> str:
return f"Results for: {query}"
@kernel_function(name="get_news")
def get_news(topic: str) -> str:
return f"News about: {topic}"
agent = ChatCompletionAgent(kernel=kernel, name="researcher")
# This prompt encourages the LLM to call both tools at once
# triggering the multi-tool batching bug
async def main():
response = await agent.get_response(
"Search the web for AI frameworks AND get the latest news on LLMs simultaneously."
)
print(response)
asyncio.run(main())
If the LLM responds with both search_web and get_news in the same turn, you'll hit the ValidationException.
Current Status
This is a known issue in the Semantic Kernel Bedrock connector. If you're running Semantic Kernel with AWS Bedrock and your agents use tools, apply the batching fix before deploying to production. Single-tool-call workflows will not be affected, but any task where the LLM is likely to batch tool calls will crash without it.
Check the Semantic Kernel GitHub issues for the latest status on an official fix.


